“电光火石”是成语“电光石火”的讹版。电光石火原为佛家语,比喻事物瞬息即逝。现多形容事物像闪电和石火一样一瞬间就消逝。
看电影《心理罪》的时候,听到李易峰说什么在电光石火之间左手换成右手,我觉得好别扭,一查,原来是我自己没文化,不过这个片子有点装逼,太神了点。
“电光火石”是成语“电光石火”的讹版。电光石火原为佛家语,比喻事物瞬息即逝。现多形容事物像闪电和石火一样一瞬间就消逝。
看电影《心理罪》的时候,听到李易峰说什么在电光石火之间左手换成右手,我觉得好别扭,一查,原来是我自己没文化,不过这个片子有点装逼,太神了点。
一般都让你去修改这个文件。
centos7是没有这个文件的,所以应该用命令:vim /etc/locale.conf 将LANG=”XXXX” 改为LANG=”zh_CN.UTF-8″。
对了,改完要reboot
如果改完没效果,得看看是不是没装中文,yum -y groupinstall chinese-support
如果yum说找不到安装包,那么只好修改yum的源了。
腾讯云提供的那个镜像三天两头出问题,动不动报错
http://mirrors.tencentyun.com/centos1/7/updates/x86_64/repodata/repomd.xml: [Err no 14] curl#6 – “Could not resolve host: mirrors.tencentyun.com; No address asso ciated with hostname”
这个似乎是要修改dns解析地址,有人说加什么8.8.8.8就好了
其实没什么用,腾讯云的镜相完全是垃圾。
直接访问不了。

所以我觉得还是一劳永逸比较好,直接换网易的吧。
如果忘了系统是什么,先查清楚自己是什么系统,我用命令查的并没有什么卵用,得直接上云管理平台上去看,咱是centos7.2,差点还以为用的是6呢。
首先备份一下:
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
然后下载并且覆盖掉原来的文件
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo
然后再生成缓存,顺带清一下垃圾
yum makecache && yum clean all
最后一步很重要,修改一个文件。
cd /etc/yum.repos.d/
看到三个文件repo,一个是刚才备份的,一个是刚才覆盖进去的。
那就编辑剩下那个吧
vim CentOS-Epel.repo
里面有个baseurl,原来带着$search和另外几个变量呢,说明这是腾讯云提供你可修改的查询链接。
直接改成baseurl=http://mirrors.163.com/centos/7/os/x86_64/repodata/repomd.xml
完事了。
之前装git失败,四个包下载成功1个,现在安装git,直接一步成功。
今天突然想到在windows下使用vim,又记得原来vim我好像已经安装过,到硬盘上一搜,结果搜到git-bash文件夹里有vim,想想这个vim应该是比较原始一点吧,就不再去找单独安装的版本了。
进入vim
随手存储一个新的文件:w something.txt
不错。
以前装git-bash的时候,没有修改设置,导致它把乱七八糟的东西统统放到administrator下面,没法管理,所以到git-hub上面下载源码的时候一般都不用它,毕竟咱基本上只是学习,并不会fork。
结果前几天发现git-hub用git命令下载源码速度是噌噌快,于是又用起来,但是一堆不知所以的源码全放在administrator里实在是太吓人了。于是想修改默认文件夹,好在网上有人已经提供了方法。
也就是修改git-bash快捷方式的“起始位置”,结果呢?没用!
ls一看,还是原来的东西嘛。
看来还是得从git-bash自身入手,找到方法如下:
打开Git安装位置下的etc文件夹,下面有个profile文件,找到
{STRINGCACHE:MD5:3d9a0cea6f64b5d1b2d8e3e21c522a2d}增加两行,修改后结果如下:
{STRINGCACHE:MD5:ac9ca5b0d50513c9edd064394aec55e0}如果找不到那几行,也无所谓,直接在末尾加就好了
不过我改完一打开看 No such file or directory
吓我一跳,原来是没创建目录,先建好了再说啊。
修改快捷方式那个,完全是个屁。没用的。至于说能不能把启动命令 cd加到快捷方式里,我是不知道。
有一套免费且漂亮的源码。
不知道谁放网上的。
版本号还按最新版写的,但是安装完了你看不到到底是什么版的。
几天前我费了点周折把它安装上线。
然后发现其中有一部分采集功能隐约是不可用的。
真的是隐约。
感觉还有救。
不想放弃。
毕竟这个采集的可用的是某宝的API,光明正大,不至于偷偷摸摸吧?
按照该公司的说明关注了公众号,拿到了采集功能所需的KEY(不是某宝的KEY)。
OK,进到相关采集页面,默认采30页,1页、2页、3页……最后毛都没有。
好吧,没报错,没说不能采,那么应该是可以的。
过了几天,我也知道写这套源码的公司不想免费了,不维护免费版了,但是由于网上的人说新版安装完的版本号和旧版一样,所以我也心存侥幸,想看看是不是运气不错,还能用。
今天晚上就专门来修理这采集模块。
首先看到了一个奇怪的错误, Illegal mix of collations (gbk_chinese_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE)
研究了半天,无非就是编码不一至的问题。
为什么编码不一致的,因为为了避免重复入库,采集程序拿新采回来的数据去Like库里的数据,如果是一样的,就不入库了。
这个好啊,但是由于新采的数据可能是gbk的,而库里的字符是utf8的,所以就出问题了。
当然这是我的分析,实际情况复杂得多,mysql默认的collation是utf8,但有两个变量死都是latin,set几次一重启就回来了。
而这个数据库当初安装的sql脚本设置的字符默认是gbk,但是实际上因为我安装时的设置,把它弄成了utf8,具体到出错的表,它的collation又是gbk。
我一怒之下,把所有能设成gbk的都设了,但是历史数据是不能改的。
然后在mysql_query方法执行前加入了set names gbk。
结果是页面上全是乱码。
好吧,我改成set names utf8。
然后把报错的那两个字段的排序改成utf8,其他不变。
结果呢,页面显示是不出错了,但是那个mix错误还在,因为每次Like的时候还是会遇到gbk。
于是我找到like前的准备语句,用iconv方法把字符串先转成utf8再说。
结果呢,mix问题不存在了。
但又遇到了Warning: Illegal string offset问题,网上的人说是因为数组为空,好吧,我做一下检查,如果数据为空就不入库。
结果发现没用,因为入库的数组本身并不是空的,只是数组没有内容。
嗯,好坑啊。
所以我决心把整个代码都给看一下,梳理一下采集的流程,找到错误最开始的地方。
可我没有在本地安装开发环境,完全是在线上调试的。
线上嘛,你只能看到一部分的错误,有些东西你是看不到的,因为有些错误被程序给处理掉了。
最后找到采集列表的部分,把curl拿到的原始数据写到一个文本文件上(没有专门的写日志语句只好自己撸fsopen了),结果很顺利,得到了一个很短的json:
{“state”:”0″,”msg”:”\u514d\u8d39\u7248\u4f18\u60e0\u5238\u670d\u52a1\u5668\u5df2\u5173\u505c\uff01″}
然后把这玩意用js的decodeURIComponent一处理,结果如下:
{“state”:”0″,”msg”:”免费版优惠券服务器已关停!”}
真是心都凉了。
其实我一开始是把那个采集目标页访问过了的,明明可以访问,我就不明白怎么用浏览器可以,用curl就不行,难道非要我假装成浏览器才行吗?
不过代码也没仔细看完,估计并不是直接用原始URL,可能是什么API的URL吧。
算了,暂时不理会了。
这件事情最神奇的是:刚装完这套代码的时候,遇到有些页面报fatal错误,说找不到class,我一开始眼尖,发现代码里有时候大写有时候小写,大小写和文件名还不一致,比如有个Page.php文件是大写开头的, 结果代码里一会儿大写一会小写,所以我以为是大小写问题,冲这个问题想了好多办法。结果发现根本不是。
后来我下载了“另一个”版本的源码,覆盖了文件之后问题自动就好了!
其实真不是大小写问题。
因为今天又出了这个问题。
我认真搜索一下,有人说这是命名空间的问题,因为同样用这个类来实例化,有时候他们写成new etc\framework\page,有时候写成new etc\framework\page().
其实我以前没想过php还可以这么干,直接写个路径在这里new?原来这个就是命名空间的效果。
当我以为完全是命名空间的锅的时候,发现问题的触发因素了:
一搞数据库,页面就出这个问题。
特别是测试采集报错的时候,随机性地出现甲乙丙丁不同的页面报fatal错误,同一个页面,一会儿正常,一会儿说找不到。
不搞采集,直接开着phpmyadmin,也会出现这个事情,一关掉一重新登录,一切又正常了。
真的是神奇的代码。
为了这么一个不是问题的烂问题,我竟然花了一个晚上!
影影绰绰学了不少东西,实际上屁用也没有,就是增长了点知识和经验,下次遇到类似的问题,只能说可以加速破案吧。
还是本地装个开发环境来得合适,目前这样搞,简直是要死人。只差没建个“日志”表直接把数据写到数据库里去了。
哦,对了,今天还玩了一堆插件的源码,帮它们改BUG。也是醉了。
自己通过接口调用自动回复功能。
一切设置都没有问题,appid和appsecret都没问题。
问题出在哪儿?
跑去把官方后台的自动回复给关掉,也没用。
后来跑到“基本配置”里一看,原来开发的配置没有启用。
![]()
当这里显示为停用的时候,才是启用状态……
我去。
没有启用怎么定自义菜单可以搞定呢?
难道自定义菜单不需要调用接口生成吗?
突然想了一下,跳转类型的自定义菜单只是向官方发送一下链接地址,在使用的时候不需要响应事件,可能因为这个,微信不需要调用响应地址,所以它允许你在url和token没有启用的情况下设置自定义菜单。
大抵如此吧。
你有没有想过给自己或者女友打造一个3D模型呢?
又或者你需要一张包含特殊人物和场景的海报,然而你不会PS,而且就算会,效果也不怎么样,毕竟光影什么的都不合适。
那些常见的3D软件又太过复杂。
网上有一款很流行的人偶制作工具,效果嘛,又太不真实了。
终于,被我从网上找到一款极度好用的免费软件,名字翻译过来,就叫造人……机器?
听起来有点污。
有意思的是,这款软件在你打开的时候,会主动提示你:这是一款造人软件,所以会有一些暴露的场面,你确定把持得住?
玩法可深可浅,你手工撸也行,到高级的时候,可以写脚本批量处理一些模型,这是开源软件,英文不烂的话,在网上可以找到相关资源哦。

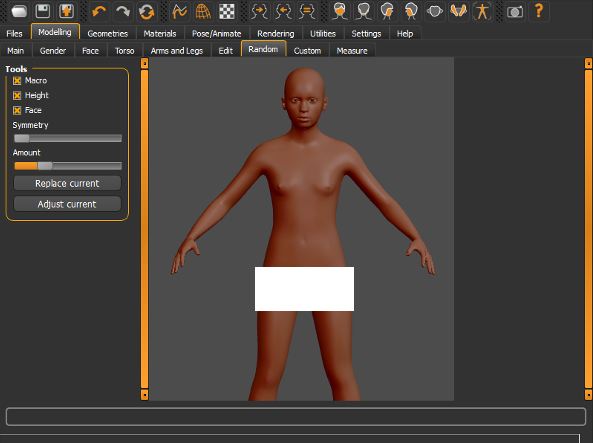


下面来欣赏一下效果:

忍者

真实的lady

运动

有点污,这是要干啥?

屎了
下载链接:https://pan.baidu.com/s/1c1SmpiC
获取密码请扫码关注

百度网盘只有100多K的时候,git能达到300多k。
而直接在github上用浏览器下载就慢很多了。
其实我就是要下个three.js,这个玩意我在不同的电脑上下载了N次了,但是当前这台电脑上好像真没有。带示例的150多m,不过很值。
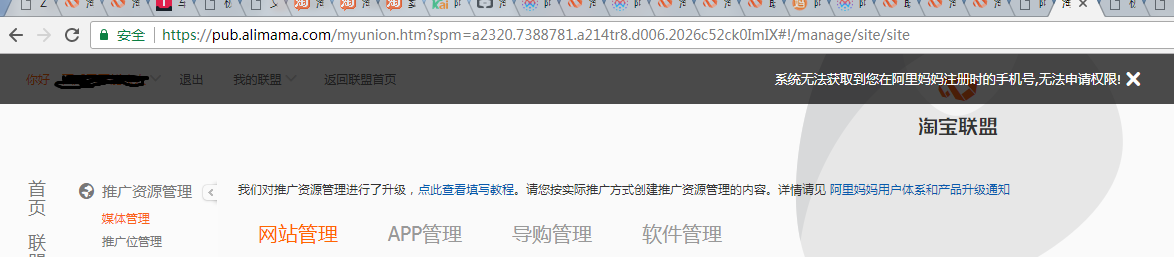
申请淘宝客app key的时候,遇到提示“系统无法获取到您在阿里妈妈注册时的手机号,无法申请权限!”
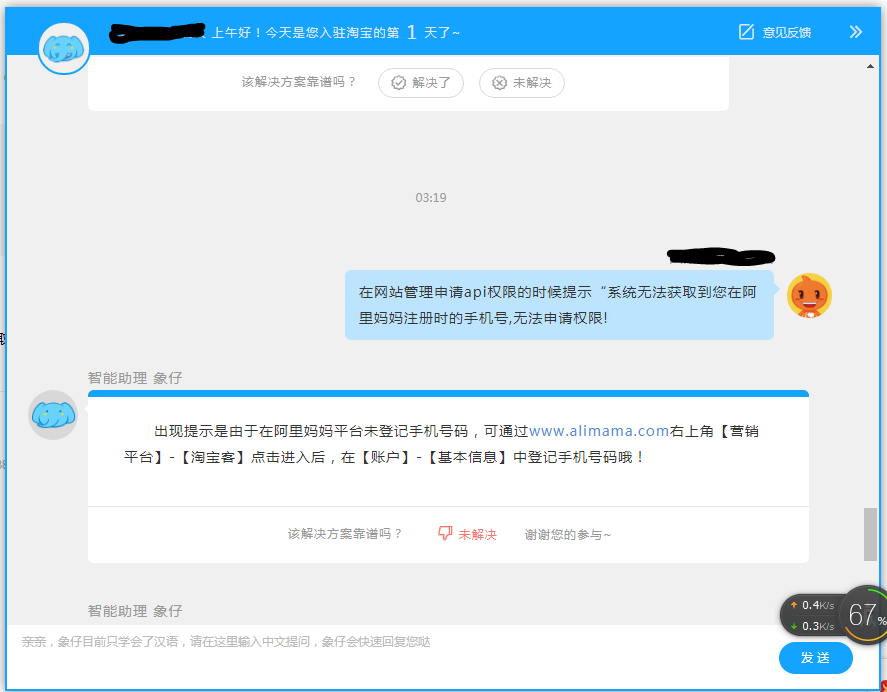
淘宝万象给的答案是错误的,你必须从首页中进入产品,然后点淘宝联盟,然后再进入“商家后台”,再点账号。这个时候一定不要被右边的提示语给吓着了,点右边的按钮就好了。
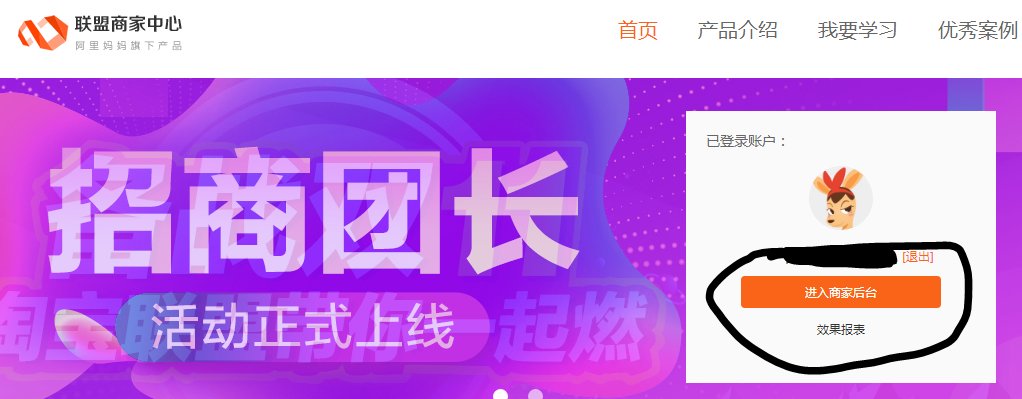
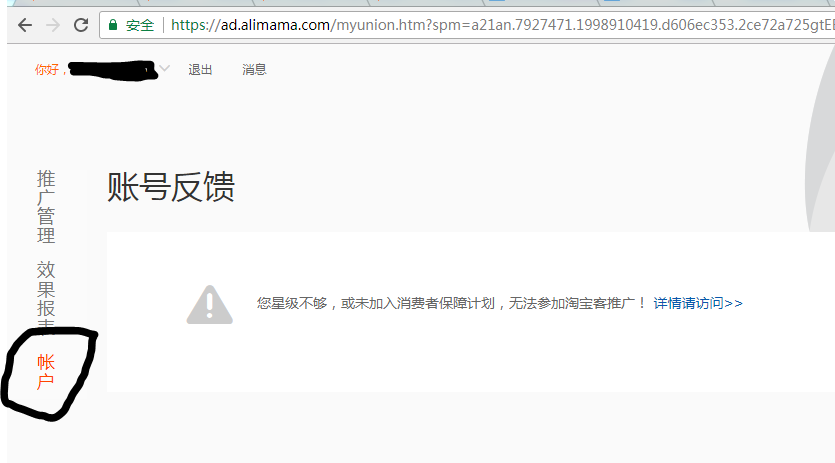
害我半夜睡不着,折腾死人。